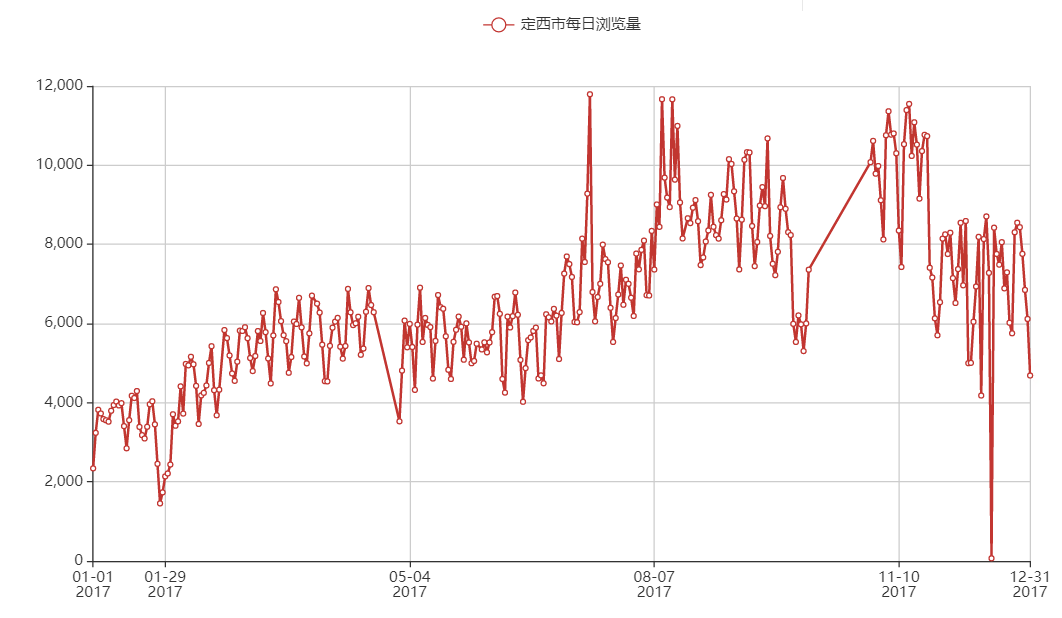
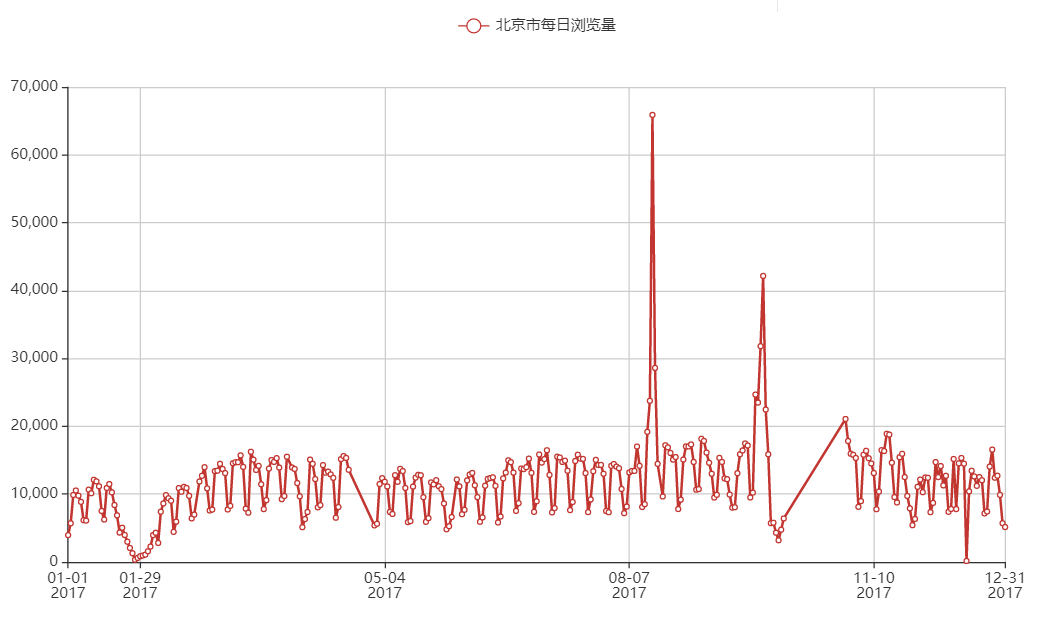
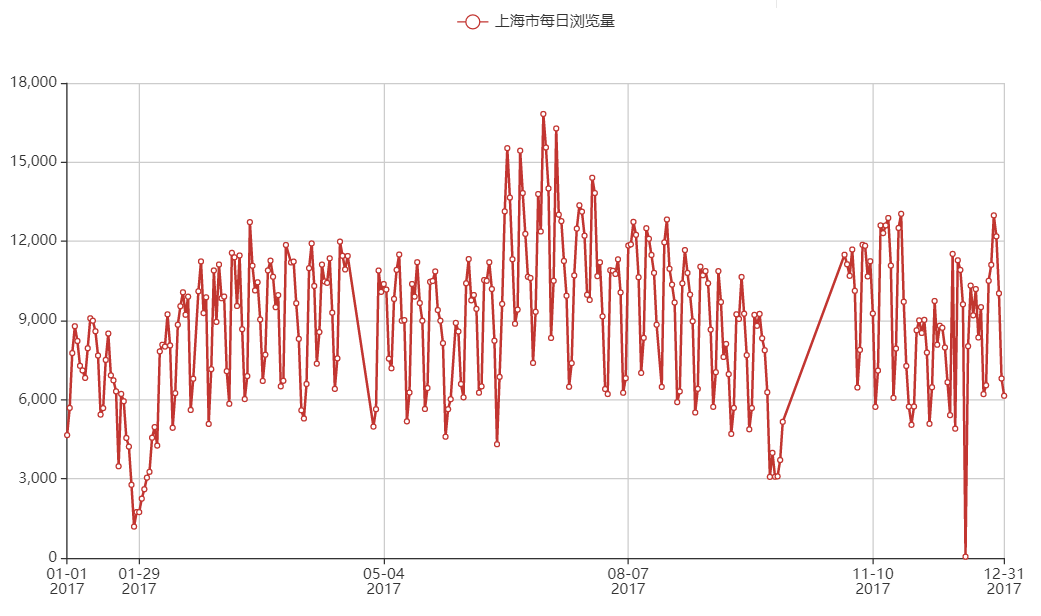
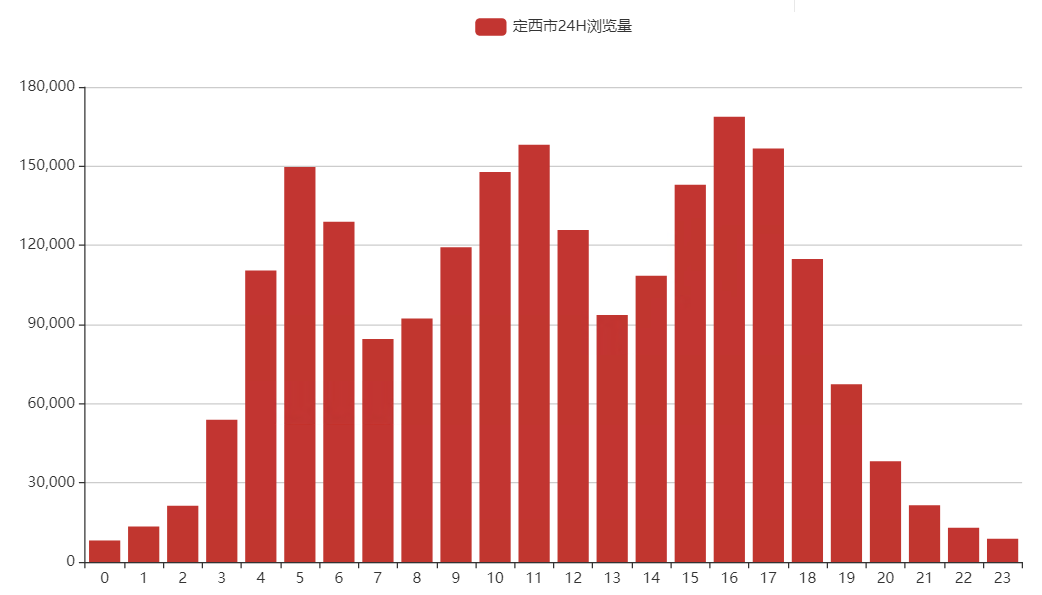
现在定西之谜有两点:
- 定西市本身没有知名研究机构,为撒在 scihub 上浏览量那么高?
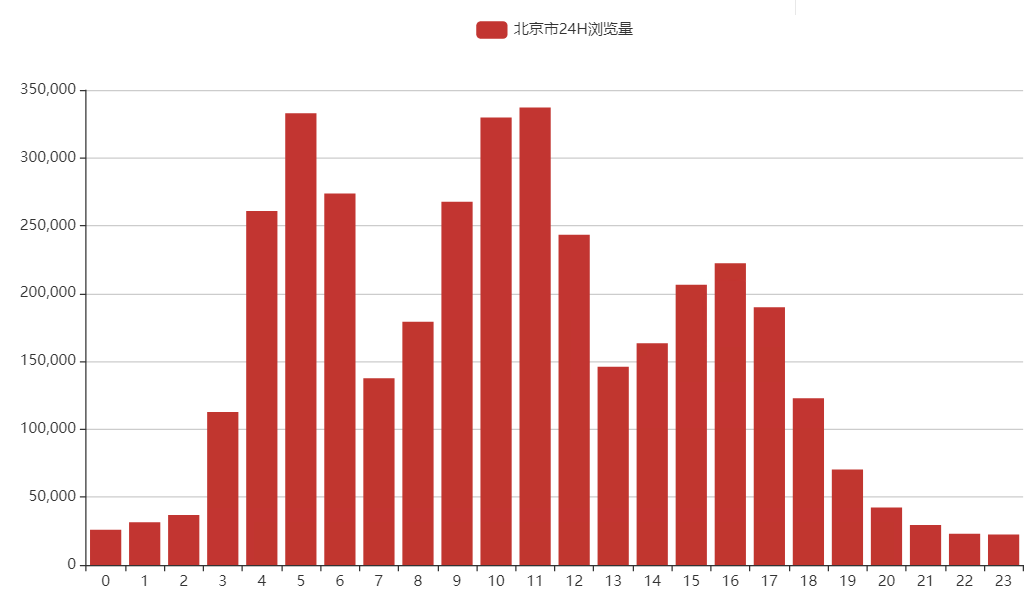
- 一般城市的自然流量在24小时内只出现2个峰值,为撒定西市有3个峰值?(PS.其实中国其他城市也是出现3个峰值,只是除了定西以外,其他城市16点的那个峰值没有那么大)
综合楼上的观点们,有两种解释:
- 虽然数据集里记录的城市是定西市,但是可能是解析错误,那些流量本应属于其他城市的数据。
- 其他地方的人,甚至是其他时区的人挂的代理。
我下载的数据是2017年的,现在是2022年,上 scihub 是毫无阻碍的,不知道2017年的时候是不是跟现在不一样。一般来说,只有访问不了此网站却需要访问时才需要代理,美国那边不是本来就没有访问障碍的嘛?
2017年总浏览量排名最高的前三个国家分别是中国、印度、美国,接下来分别画下印度和美国浏览量最高的前两个城市哈。
印度
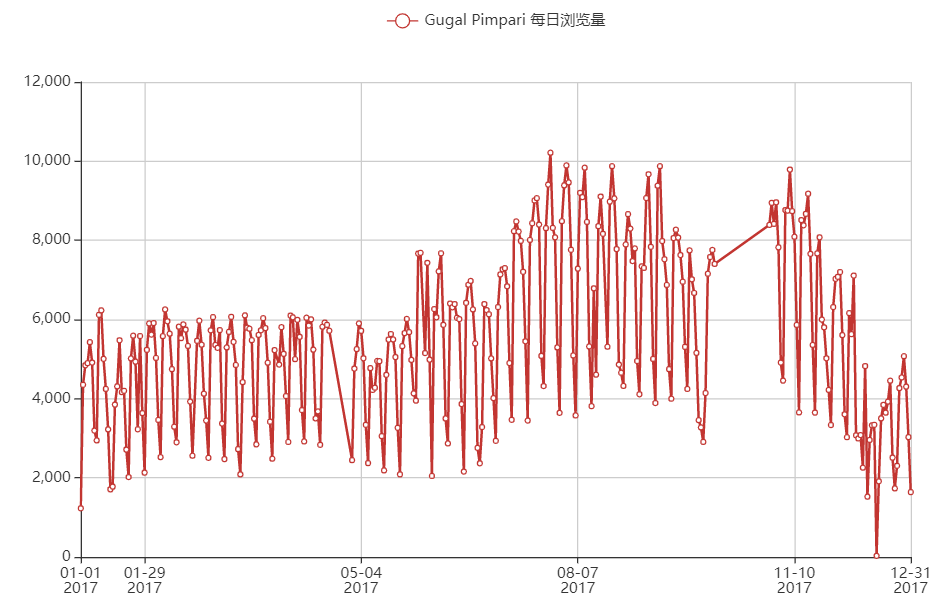
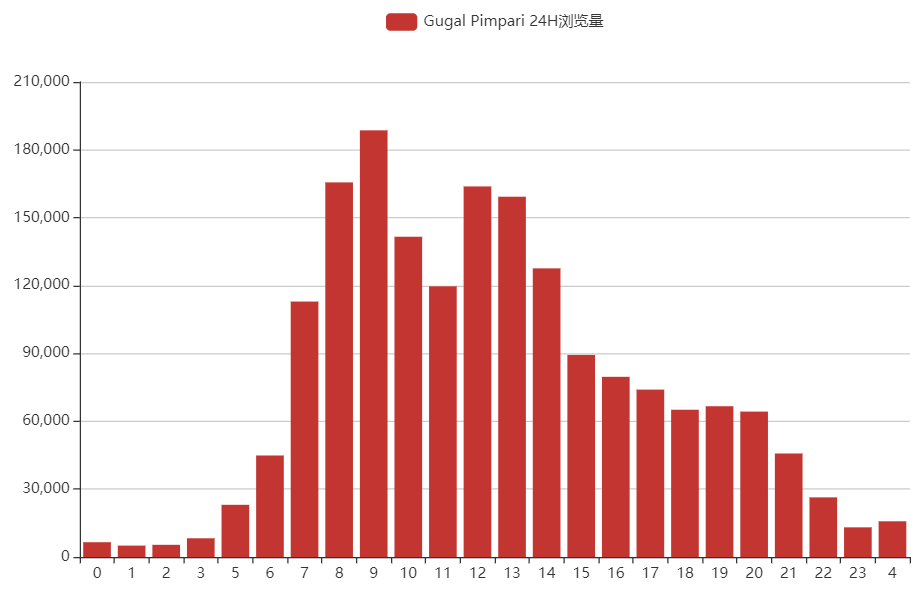
Gugal Pimpari
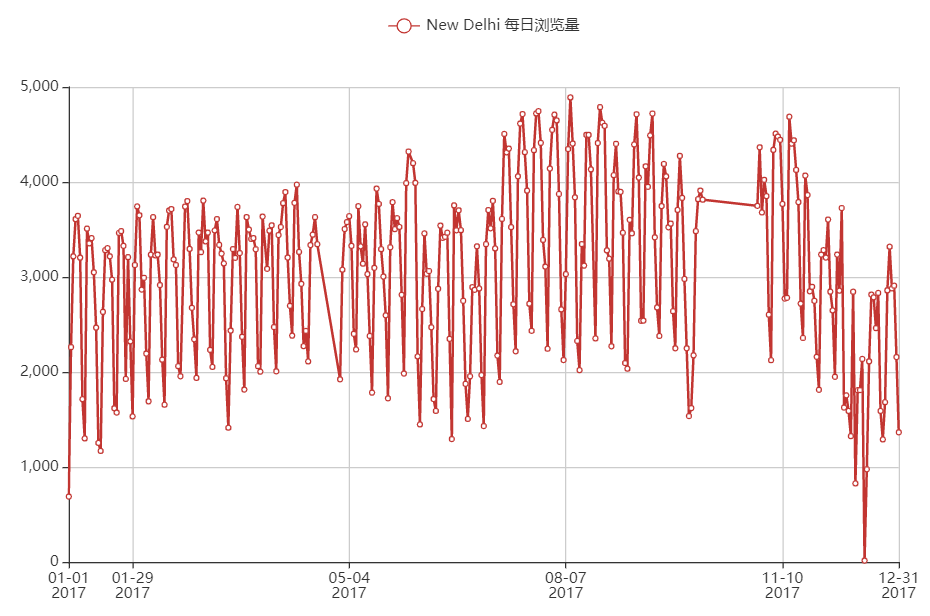
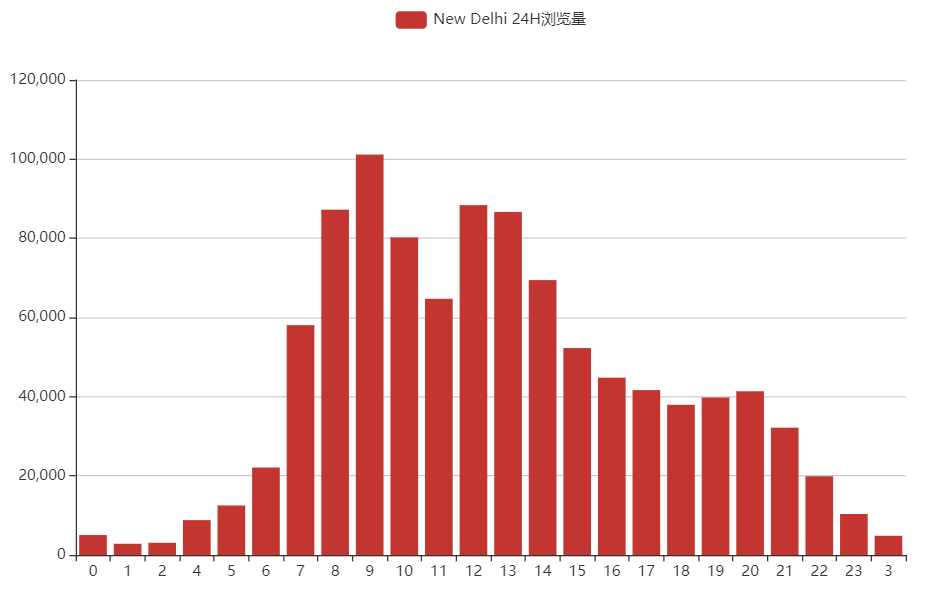
新德里
美国
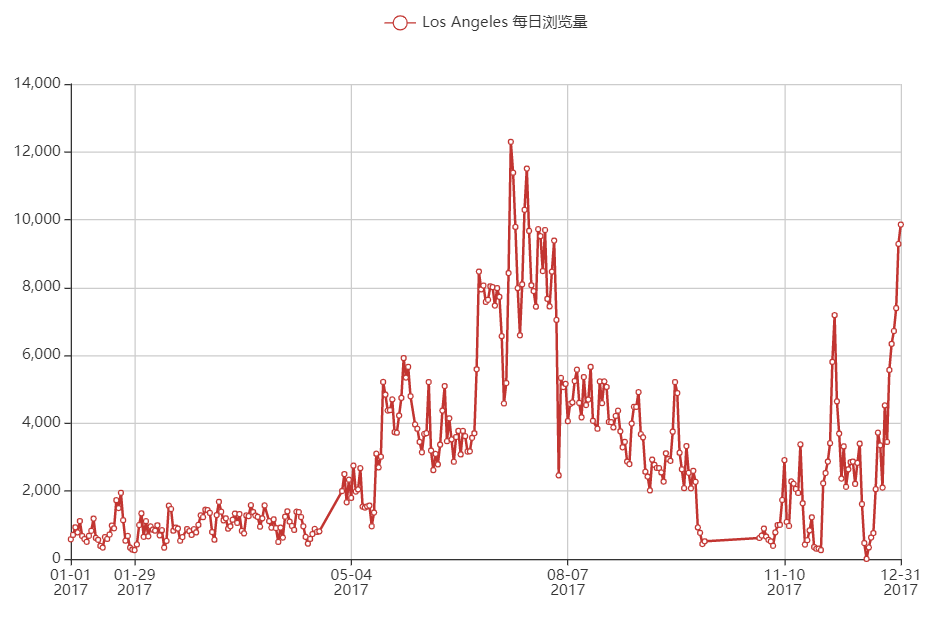
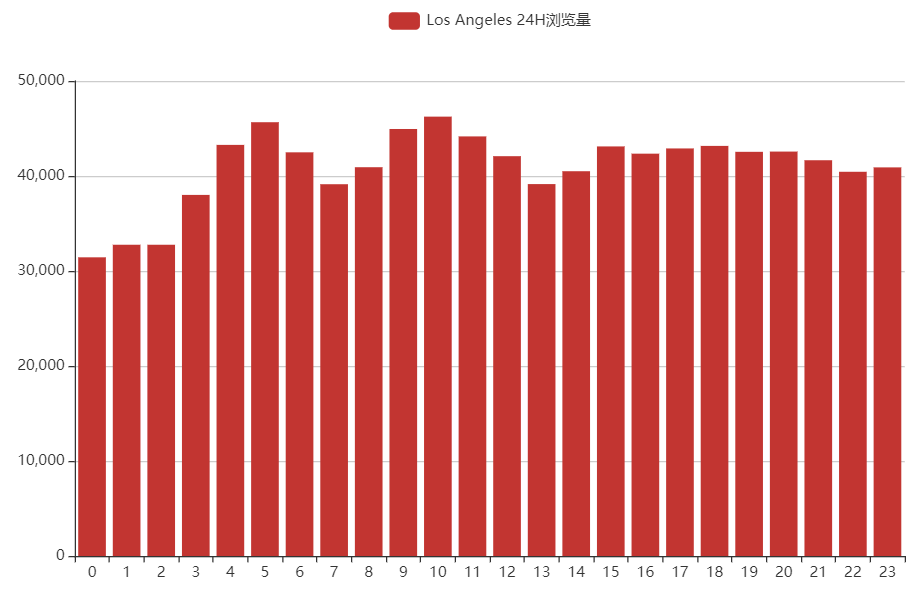
洛杉矶
芝加哥
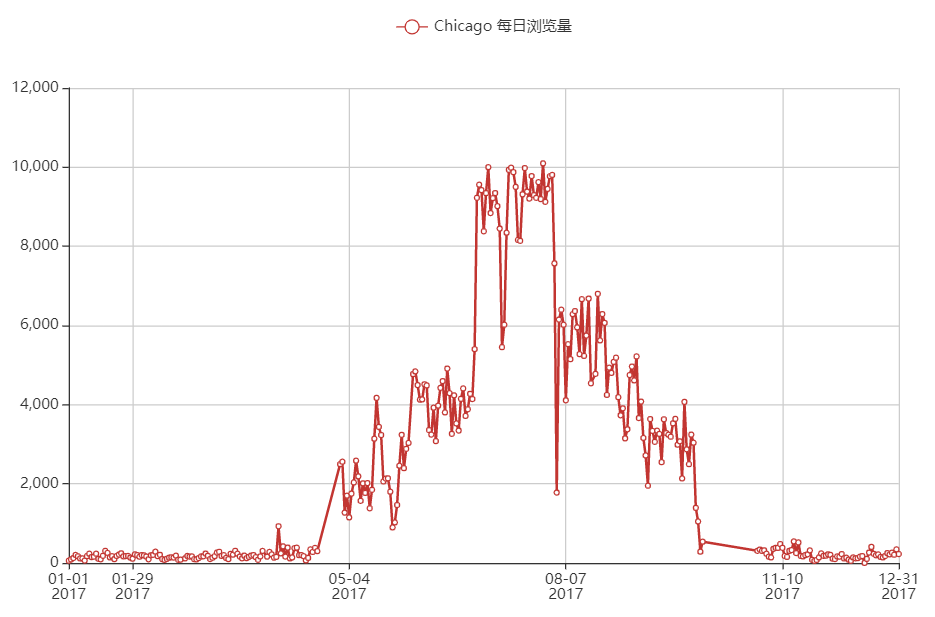
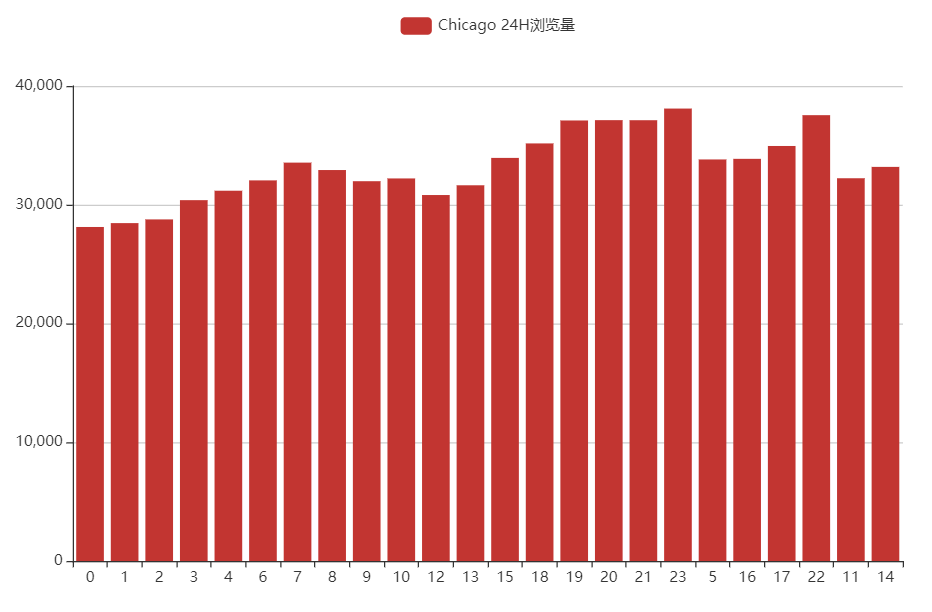
综上,美国浏览量前2的城市大多数都是挂的代理,24小时浏览量差得不多;印度浏览量前2的城市看起来像是多数都是正常的自然流量,因为确实24小时内只有2个峰值。
我觉得@yufree 说的有道理,定西市的流量里应该是既有自然流量,也有非自然的。照着思路把周末的拆出来看是这样的:
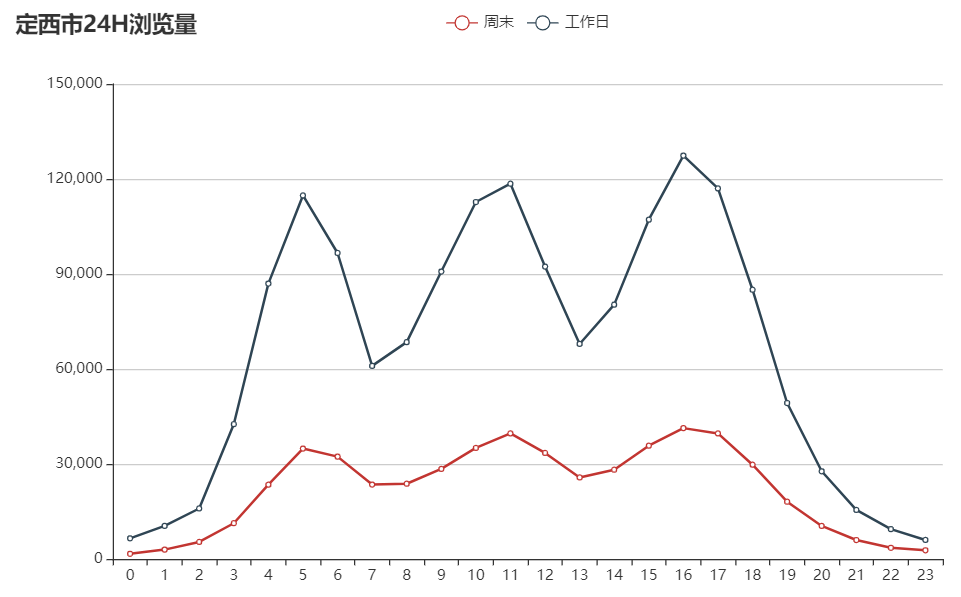
取出那些日期对应一周的第几天,一周的第1天是星期日,第7天是星期六,看看这三个城市的。
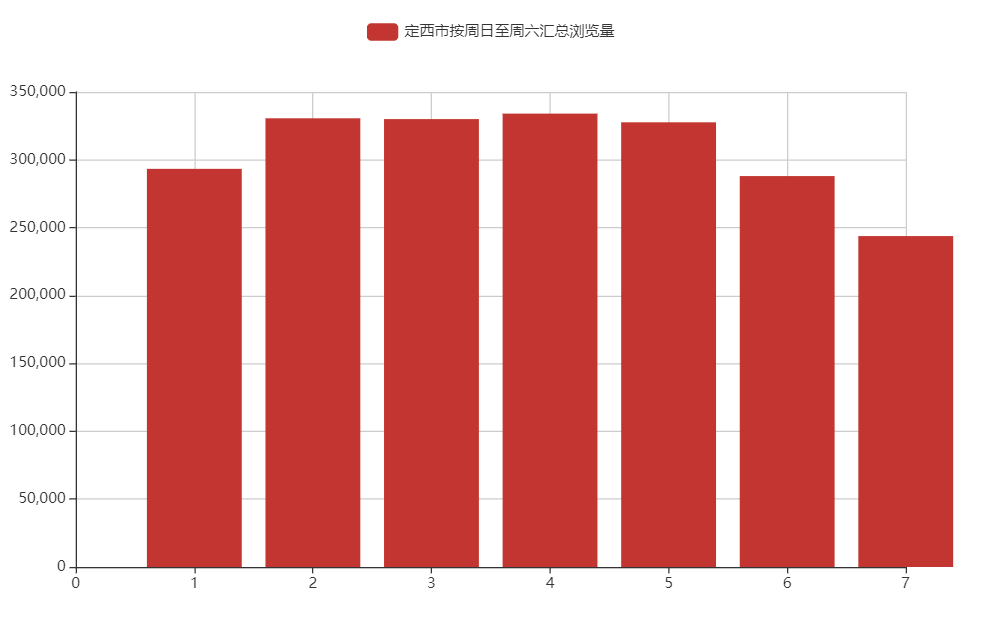
中国 定西:
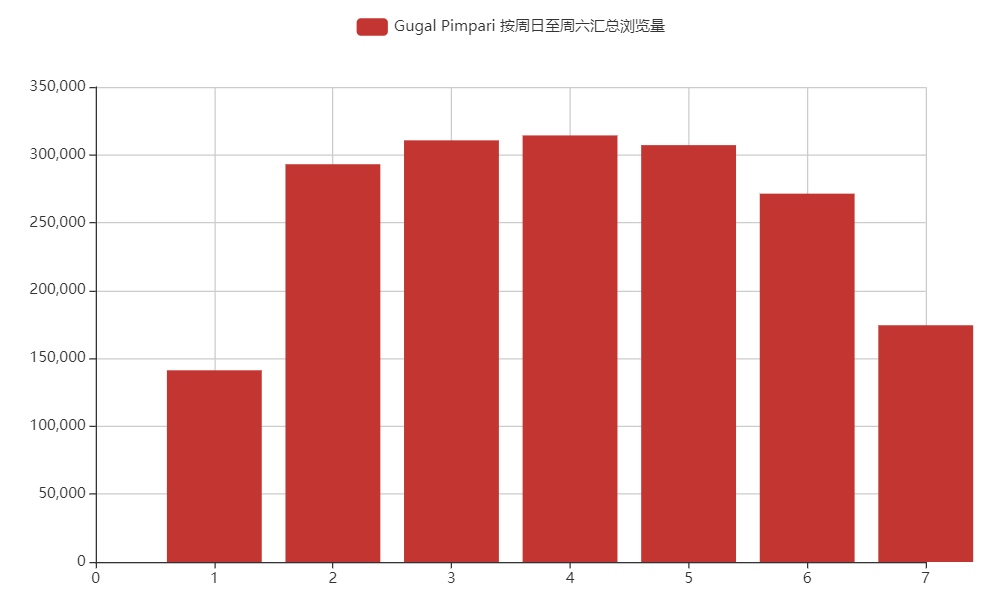
印度 Gugal Pimpari
美国 洛杉矶
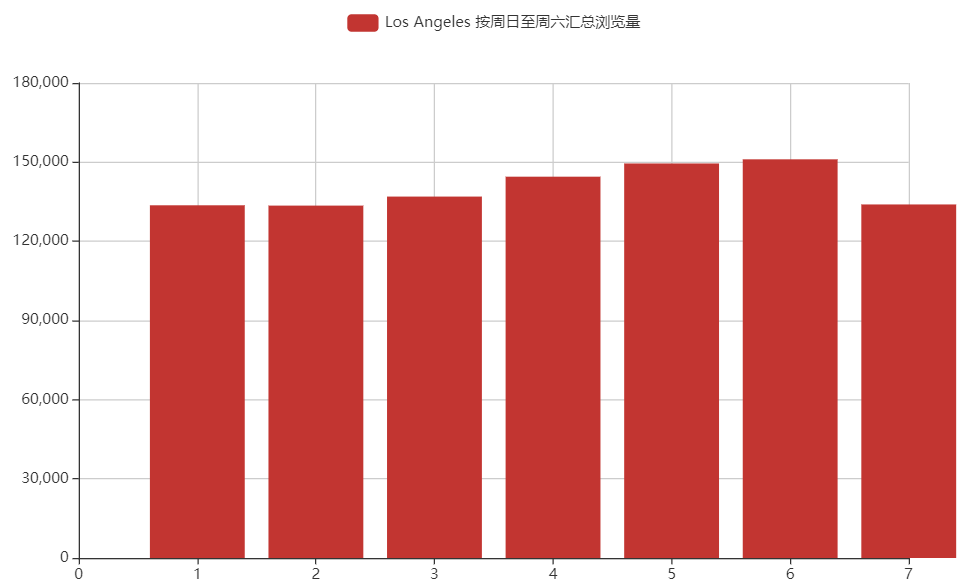
只看国家的,为了使热力图有区分度,把中国的浏览量除以10000,把印度和美国的除以5000
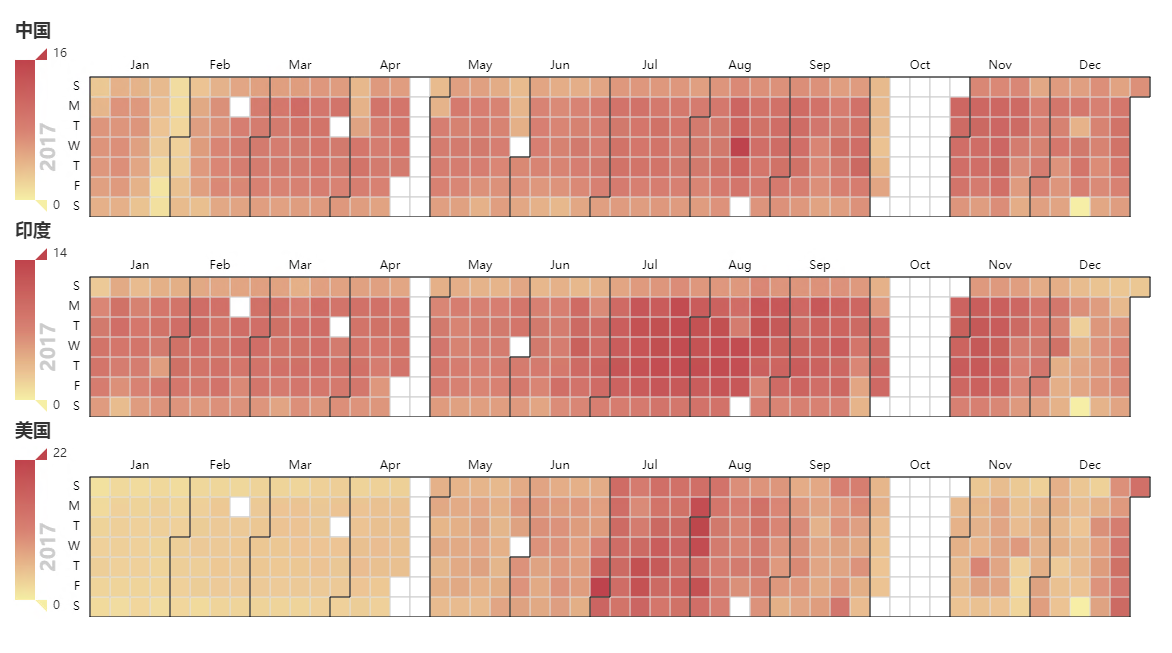
我觉得印度的流量最自然,周六周日休息。美国的流量最不自然……中国的流量自然中混合着不自然。