yufree 我翻译了您给的2个参考资料之一,如下 :
方差分析(ANOVA,以下称方差分析)是用来分析不同因子对样本的方差贡献水平的统计学过程。它源起于R。A.Fisher in 1925,关于平衡数据(每个因子水平有相同的观测数)的一个例子。
当数据是非平衡的时候,有几种不同的方法来计算方差分析中的平方和(sums of suqare)。至少有三种方法,通常称为Type I, II, III 平方和(这个名称最初好像是从SAS包中被传播到统计界世界的,并且现在已被广泛传播和应用)。空间使用哪个类型的平方和被统计学家广泛讨论 。然而,对数据使用不同的假设,比如Type I, II III平方和,来进行检验,是非常有必要的。
想象一下,假设有一个模型,含有两个因子A和B,因此,会有两个主效应和一个交互效应AB。整个模型应该是SS(A, B, AB)
其它的模型可能类似:SS(A, B)表示 模型没有交互效应。SS(B, AB)表示模型的因子A的效应不明显。诸如此类。
特定的因子(包括交互效应)的影响,可以通过对不同的模型进行检查来检验出来。比如,为了确定交互作用是否显著,将会对模型SS(A, B, AB)和SS(A, B)两个模型进行F检验。
非常容易通过平方和的增加来表示这些模型的不同。让:
SS(AB | A, B) = SS(A, B, AB) – SS(A, B)
SS(A | B, AB) = SS(A, B, AB) – SS(B, AB)
SS(B | A, AB) = SS(A, B, AB) – SS(A, AB)
SS(A | B) = SS(A, B) – SS(B)
SS(B | A) = SS(A, B) – SS(A)
这些表达式表明了平方和增加的不同。比如SS(AB | A, B)表示“交互作用在主效应之后”,以及SS(A | B)表示“A主效应的平方和在B的主效应平方和之后,并且忽略交互作用”。
不同的平方和类型基于在执行的时候,模型减少的阶段(可以理解为逐步法的减少)。尤其是:
Type I,通常被称为“序贯”平方和。
SS(A) for factor A.
SS(B | A) for factor B.
SS(AB | B, A) for interaction AB.
这个用来检验因子A的主效应,在A的主效应之后是B的主效应,然后在所有主效应后是AB的交互作用。
因为序贯的天然属性,以及两个主效应的检验是按一定顺序进行的这个事实,对于非平衡数据,这个类型的平方和会根据主效应的顺序给出不同的结果。
对于非平衡数据,这个方法用来检验边际均值效应。对于特定的项,这意味着结果会依赖于实际的样本量,也就是说,特定样本的比例。换句话说,它检验第一个因子时并不考虑控制其它的因子。(对于以后的讨论和实例,可以看Zahn )
注意,在处理非平衡数据时,这经常不是一个有趣的假设。
Type II:
SS(A | B) for factor A.
SS(B | A) for factor B.
这个类型在其它主效应后检验每个主效应
注意
注意没有明确假设交互项(换句话说,你应该先检验交互作用(SS(AB | A, B)),并且仅当交互作用AB不显著的时候,继续分析主效应。)
如果实际上没有交互项,Type II在统计上比Type III有更高的功效。(详细情况参考Langsrud )
计算上,这等于使用不同的因子顺序,执行Type I分析,并且得到合适的结果(然后,在其它效应之后运行一个主效应,在上面的例子中)
Type III:
SS(A | B, AB) for factor A.
SS(B | A, AB) for factor B.
这个类型在其它主效应和交互作用之后检验一个主效应。这个方法因此可以在存在交互项的时候使用。
然而,如果存在交互作用,解释一个主效应的意义通常也不是非常有意思。(总的来说,如果存在交互作用,主效应应该在后面进行分析)
如果交互项不显著,Type II的功效更高。
注意:当数据是平衡的时候,因子是正交的,Type I, II, III给出的结果是一样的。总结来讲,是控制其它因子水平的情况下,检验一个因子的显著性。这等于使用Type II或III 平方和。大体上,如果没有交互作用,Type II功效更高,遵守边际原则。如果存在交互作用,Type II就不太合适了,不过仍然可以使用Type III。但是结果解释应该小心(存在交互作用的时候,主效应很难解释)。
方差分析和R中的aov函数
方差分析和R中的aov函数执行序贯平方和(Type I)。就像上面提到的,这个很难检验假设的效应,因为,计算一个因子的效应时,其它因子的水平是变化的。这意味着结果仅可以解释在(非平衡)数据样本中出现的特定水平的观察值。幸运的是,基于以上讨论,这可以很清楚的直接与Type II的结果做对比。
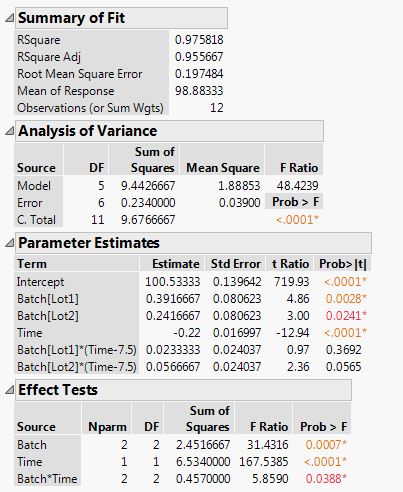
因为Type II平方和在其它所有主效应之后检验一个主效应,并且假设没有交互作用。可以使用anova()函数得到正确的平方和,并且可以变化因子顺序。
比如,假设一个数据框。(search) 响应变量是用户使用信息检索系统找到相关答案的时间(time),用户被分成2组使用不同的系统进行搜索(sys)。他们也被要求使用一些不同的索引条件(topic).
Type I SS in R:
anova(lm(time ~ sys * topic, data=search))
如果数据是非平衡的,你使用下面的命令会得到稍微不同的结果。
anova(lm(time ~ topic * sys, data=search))
使用上面每一条命令,Type II平方和通过每个结果的第二行得到。(因为Type I平方和,第二个元素将会在第一个因子后成为第二个因子)。也就是,你通过第一条命令,得到了topic的Type II平方和结果。通过第二条命令,得到了sys的Type II平方和结果。
Type III SS in R:
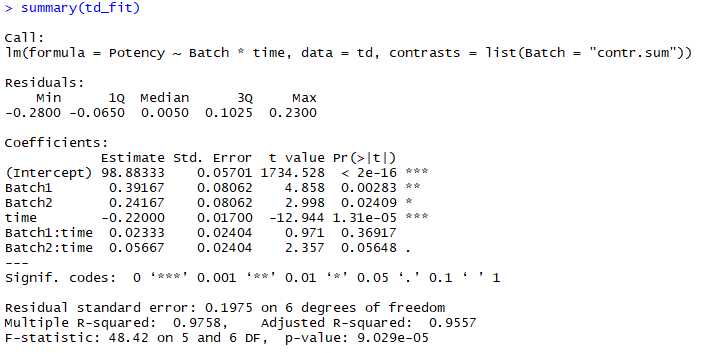
这与Type II的结果比稍微更复杂一点。首先,应该在R中设定contrasts选项,因为多因子方差分析模型是过度参数化的,有必要选择一个对比对象,设定平方和是0,否则方差分析将会在假设检验上给出错误结果。(默认的对比类型不满足这个要求)
options(contrasts = c(“contr.sum”,”contr.poly”))
然后建模:
model <- lm(time ~ topic * sys, data=search)
最后,对每个模型元素调用drop1函数.
drop1(model, .~., test=”F”)
这个结果给出的就是Type III的平方和,包括了F检验的P值。
使用car包计算Type II和Type III平方和。
使用其它更方便的方法得到Type II, III平方和结果是使用car包,它定义了一个新的函数,Anova(),可以直接计算type II和Type III平方和。
Type II,使用上面相同的数据。
Anova(lm(time ~ topic * sys, data=search, type=2))
Type III:
Anova(lm(time ~ topic * sys, data=search, contrasts=list(topic=contr.sum, sys=contr.sum)), type=3))
注意:再次强调,因为SS是根据交互作用计算的,对于Type III你必须指定contrasts 选项来得到更合理的结果(这里是解释)
背景: 平方和的由来
源头
如果有一个类型I平方和和类型II平方和, 就得到了一个问题。有更多的吗?很幸运,实际上,有4个平方和类型,每个都有他们相关的统计方法。这4个类型,称为Type I, II, III, IV(Goodnight 1978)。虽然我们本课程只使用类型I和类型II,这里是4个类型的介绍。
Type I (sequential or incremental SS/序贯平方和)
Type I计算平方和时,按顺序考虑每个因子,按他们在模型中列出的顺序。类型I平方和对非平衡数据,多因子结构的计算可能没有太大用处,但是可能对于平衡数据的嵌套模型会非常有用。类型I平方和对于简单多项式模型同样比较有用(比如回归分析)。允许在使用更复杂模型(二次,三次等)前,使用简单因素(比如线性)来解释同样变量数的变异。并且,通过将类型I与其它类型比较,提供了更多的非平衡数据差异的信息。类型II和类型III平方和被大家熟知为部分平方和,每个效应是根据其它效应进行调整的。
Type III
类型III是部分平方和方法,但是它比类型II更容易解释,所以我们从这里开始。在这种模型里,每个效应是根据所有其它效应来调整的。对于某个数据集,如果缺失值被最小二乘解的值代替,类型III平方和将会产生和类型I一样的平方和。类型III平方和与耶茨加权平方和分析方法一致。如果使用这个平方和方法,要求在有交互项的时候对比主效应。(类型II并不做这些,顺便,很多统计学家说不根本不应该做)。特别是,主效应A和B根据交互作用A*B调整,并且所有这些项都在模型中。如果模型只包括主效应,你会发现类型II和类型III分析结果一样。
Type II
类型II部分平方和有些难理解。大体上,类型II平方和对于可能是主效应或交互作用的效应U,根据效应V来调整,并且只有当V不包括U的时候。特别是,对于有交互作用的二因子结构,主效应A和B不是根据AB交互项调整的,因为这个交互项包括了A和B。因子A根据B调整,因为B不包括A,类似的,B根据A调整。最终,AB交互作用根据两个主效应的每一个来调整,因为没有一个主效应同时包括A和B。换句话说,类型II平方和根据所有其它不包括完整效应项目的因子进行调整。在一些情况下,你可以把它想象成一个序贯部分平方和,在里面,你允许低阶项解释尽可能多的变量,在让高阶项进入考虑之前,根据另一个进行调整。
Type IV
类型IV函数最初是在考虑到一些空格的情况下被设计出来的,同样被熟知为"radical"数据丢失。类型IV平方和的原则是非常复杂的,并且仅可以在一般结构方程的框架下进行讨论。应该注意的是类型IV函数不是当有空格的时候唯一的选择,但是等同于没有空格的类型III的结果。