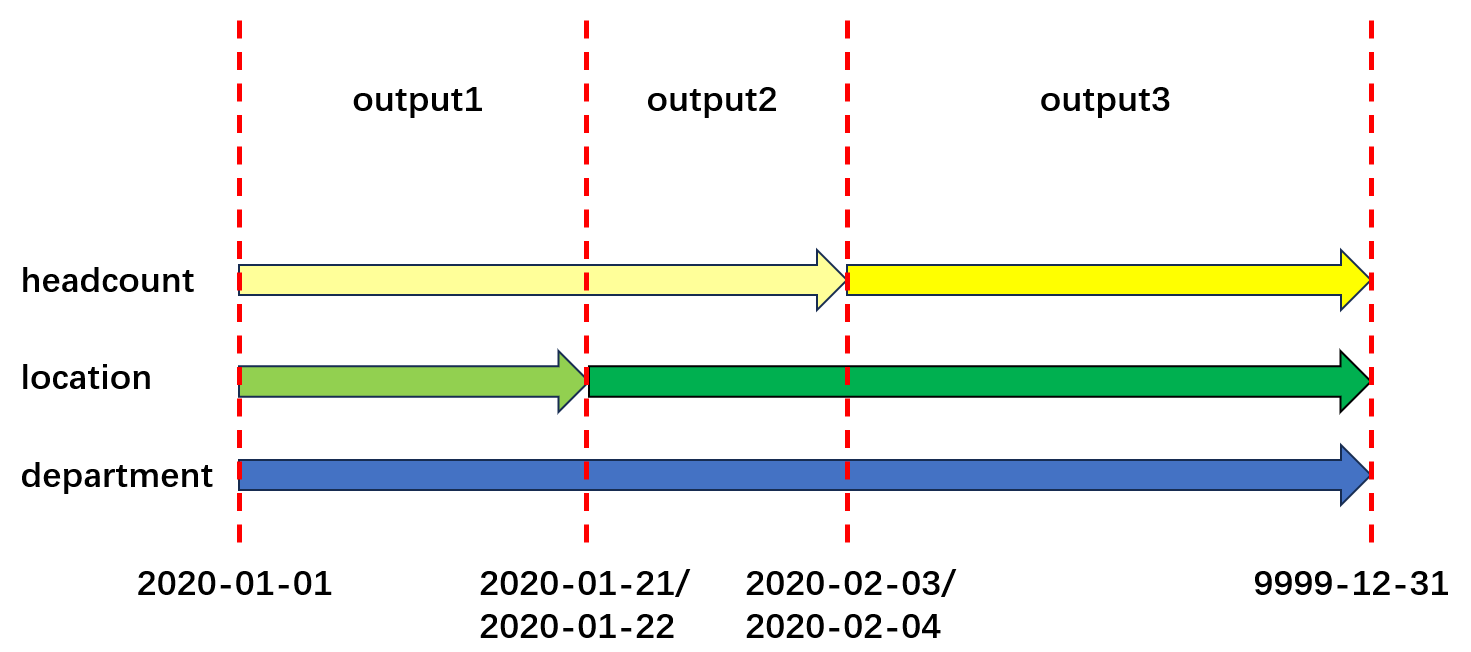
从目前数据的逻辑看,这个原始表格看来记录的是部门的变动日志,包括地点人数等属性。
常规的长表转宽表方法(pivot_wider) 可能会枚举所有可能的type组合,在这种情况下不大可能处理得好
我的尝试是从头构建目标表格: 先初始化一条包含所有type的记录的“数据对象”,随后按date_from排序,有一条改动就更新对象,并添加一个记录。
library(dplyr)
data <- data.frame(
id = c(1, 1, 1, 1, 1),
type = c("department", "headcount", "headcount", "location", "location"),
value = c("finance", 10, 15, "DC", "NY"),
date_from = as.Date(c("2020-01-01", "2020-01-01", "2020-02-04", "2020-01-01", "2020-01-22")),
date_to = as.Date(c("9999-12-31", "2020-02-03", "9999-12-31", "2020-01-21", "9999-12-31"))
)
init_date = min(data$date_from)
## 初始化数据对象
data_obj=
data %>%
filter(date_from == init_date) %>%
select(id,type,value,date_from) %>%
tidyr::pivot_wider(names_from = type,values_from = value)
data_change = data %>%
filter(date_from> init_date) %>%
arrange(date_from)
## 更新数据对象,用records生成记录
records =data_obj
dummy= sapply(1:nrow(data_change),function(i){
a_type=data_change$type[i]
data_obj[[a_type]] <<- data_change$value[i]
data_obj$date_from <<- data_change$date_from[i]
records <<- rbind(records, data_obj)
})
records
#> # A tibble: 3 × 5
#> id date_from department headcount location
#> <dbl> <date> <chr> <chr> <chr>
#> 1 1 2020-01-01 finance 10 DC
#> 2 1 2020-01-22 finance 10 NY
#> 3 1 2020-02-04 finance 15 NY
<sup>Created on 2024-04-15 with reprex v2.0.2</sup>