我是本书的作者:张敬信
说明:本书的配套课件已做了整合:1393页PDF版完整课件,也已在本论坛分享:
张敬信:分享我的1393页《R语言编程:基于tidyverse》完整课件
可以说,看课件也基本等同于看原书,所以,买不买书是次要的,如果觉得书好,请帮助分享和扩散。
我最大的心愿,就是将国外已经蓬勃发展多年的,这么好用的R语言 tidyverse 数据编程技术,推广到国内,改变国内R语言不思进取,资料陈旧,越来越边缘化的现状。
我为什么这么说,可以看一下 bookdown 官网有多少基于 tidyverse 的各个研究领域的 R 新书,而国内有几本?
如果想要购买本书,可到京东、天猫、当当等平台,搜索【R语言编程】。


内容简介
这是一本基于 tidyverse 入门 R 语言编程的书,本书从基本的编程语法讲起,适合编程零基础的读者阅读。本书结合新的 R 语言编程范式,让读者学习更高效率的 R 编程,尤其是真正用整洁优雅的数据化编程思维解决一系列数据问题,包括数据清洗、数据处理、数据可视化、统计建模、文档沟通等,并在附录中将透视表、网络爬虫、高性能计算、机器学习等典型应用囊括其中,为读者提供了丰富的R实用编程案例,也可作为一本 R 语言语法大全的工具书。 本书面向热爱R语言编程的读者,适合统计学、数据分析、数据可视化等领域的读者阅读参考,也可以作为高等院校相关专业的 R 语言教材。
前言
R 语言是以统计和分析见长的专业的编程语言,具有优秀的绘图功能,且开源免费,有丰 富的扩展包和活跃的社区。R 语言的这些优质特性,使其始终在数据统计分析领域的SAS、 Stata、SPSS、Python、Matlab 等同类软件中占据领先地位。
R 语言曾经最为人们津津乐道的是Hadley 开发的 ggplot2 包,其泛函式图层化语法赋予 了绘图一种“优雅”美。近年来,R 语言在国外蓬勃发展, ggplot2 这个“点”自2016 年以来, 已被 Hadley “连成线、张成面、形成体(系)”,从而形成了 tidyverse 包。该包集“数据导 入、数据清洗、数据操作、数据可视化、数据建模、可重现与交互报告”整个数据科学流程于 一身,以“现代的”“优雅的”方式和管道式、泛函式编程技术实现。不夸张地说,用tidyverse 操作数据比 pandas 更加好用、易用! 再加上可视化本来就是R 所擅长的,可以说 R 在数据科 学领域不次于 Python。
这种整洁、优雅的 tidy 流,又带动了 R 语言在很多研究领域涌现出了一系列 tidy 风格 的包:tidymodels (统计与机器学习)、mlr3verse (机器学习)、rstatix (应用统计) 、 tidybayes (贝叶斯模型)、tidyquant 和modeltime(金融)、fpp3 和timetk(时间序 列)、quanteda (文本挖掘)、tidygraph (网络图)、sf (空间数据分析)、tidybulk (生 物信息)、sparklyr (大数据)等。
在机器学习和数据挖掘领域,曾经的 R包总是在单打独斗,如今也正在从整合技术方面迎 头赶上 Python,出现了 tidy 风格的tidymodels 包,以及新一代的用于机器学习的 mlr3verse 包,它基于 R6 类面向对象、data.table 神速数据底层和开创性的Graph-流模 式(图/网络流有别于通常的线性流)。
写作本书的目的
我发现近几年出现的 R 语言新技术很少有人问津, 绝大多数 R 语言的教师和学习者,以及教材、 博客文章仍在沿用那些过时的、晦涩的 R语法,对 R 语言的印象仍停留在几年前: 语法晦涩难懂、速 度慢, 做统计分析和绘图还行, 没有统一的机器学习框架, 无法用于深度学习、大数据、工业部署等。
有感于此,我想写一本用最新 R 技术,方便新手真正快速入门 R 语言编程的书,来为R 语言 正名。我是一名大学数学教师,热爱编程、热爱R 语言,奉行终身学习的理念,一直喜欢跟踪和 学习新知识、新技能。我对编程和 R 语言有一些独到的理解, 因为我觉得数学语言与编程语言是 相通的,都是用语法元素来表达和解决问题, 我想把这些理解和体会用简洁易懂的方式表达出来。
希望这本书能让你学到正确的编程思想,学到新的 R 语言编程知识和编程思维, 能真正让 你完成 R 语言入门或R 知识汰旧换新。
本书的目标读者
- 没有 R 语言基础,想要系统地学习 R 语言编程,特别是想要学习新兴R 技术的人。 具备一定的 R 语言基础,想升级 R 语言编程技术的人。
- 想要理解编程思想,锻炼向量化、函数式编程思维,以及真正的数据思维的人。
- 想要以 R 为工具,从事统计分析、数据挖掘、机器学习工作的人,特别是想学习使用机器 学习包(tidymodels 和mlr3verse)的人。
- 高校里对 R 语言及相关课程有需求的师生及科研人员,特别是将来想要在时间序列、金融、空间 数据分析、文本挖掘等领域使用 fpp3、modeltime、tidyquant、sf、quanteda 等包的人。
本书特色
1.内容新颖
本书绝大部分内容参考新版本 R 包的相关文档,全面采用新的 R 语言技术编写,特别强调 “整洁流、管道流、泛函流”数据科学思维(tidyverse)。
- 真正融入编程思维
很多 R 语言编程书只是罗列编程语法,很难让初学者学透它们。本书真正融入编程思维: 由编程思想引导,了解编程语法到底是怎么回事,应该用于何处以及怎么使用。
本书首创性地梳理并提出了数据编程思维,让读者有真正使用数据思维解决数据问题有了抓手:
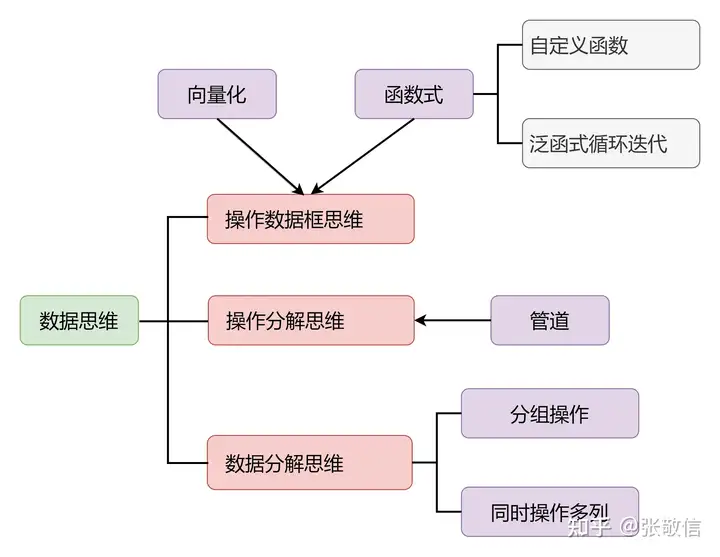
总结下来主要是以下三点:
● 将向量化编程思维和函数式编程思维,纳入数据框或更高级的数据结构中比如,向量化编程能同时操作一个向量的数据,我们将其转变成在数据框中操作一列的数据或者同时操作数据框的多列,甚至分别操作数据框每个分组的多列;将函数式编程转变成为想实现的操作自定义函数(或使用现成函数),再依次应用到数据框的多个列上,以修改列或进行汇总。
●将复杂数据操作分解为若干基本数据操作
复杂数据操作都可以分解为若干简单的基本数据操作:数据连接、数据重塑(长宽变换/拆分合并列)、排序行、选择列、修改列、分组汇总等。一旦完成问题的梳理和分解,又熟悉每个基本的数据操作,用“管道流”依次对数据做操作即可。
●接受数据分解的操作思维
比如,想对数据框进行分组,分别对每组数据做操作,整体来看这是不容易想透的复杂事情,实际上只需通过group_by ()分组,然后把你要对一组数据做的操作进行实现;再比如,用across ()同时操作多列,实际上只需把对一列数据要做的操作进行实现。这就是数据分解的操作思维,这些函数会帮你“分解+分别操作+合并结果”,你只需要关心分别操作的部分,它就变成一件简单的事情。
3.精心准备实例
讲解编程语法必须配以合适的实例来演示,也建议读者一定要将编程语法讲解与配套实例 结合起来阅读,比起将实例代码调试通过,更重要的是借助实例代码透彻地理解编程语法所包 含的编程思维。本书后半部分是 R 语言在应用统计、探索性数据分析、文档沟通方面的应用, 所配案例力求能让读者上手使用。
4.程序代码优雅、简洁、高效
本书程序代码都是基于tidyverse 编写的,自然就很优雅。此外,本书尽量采用向量化 编程和泛函式编程,更体现其简洁、高效。可以说,读者如果用这本书入门 R 语言,或者更新你的 R 知识库,就会自动跳过写烦琐、低效代码的阶段,直接进入“高手级”代码的行列。
本书内容安排
本书的结构是围绕如何学习 R 语言编程来展开的,全书内容共分为 6 章。 冯国双老师在《白 话统计》序言中写道:
“一本书如果没有作者自己的观点, 而只是知识的堆叠,那么这类书是没有太大价值的。”
尤其在当前网络发达的时代,几乎任何概念和知识点都可以从网络上查到。但有一点你很 难查到,对于编程书来说,那就是编程思维。本书最大的特点之一就是无论是讲编程思想还是讲编程语法知识点,都把编程思维融入进去。
很多人学编程始终难以真正入门,学习编程语言要在编程思想的指导下才能事半功倍。本 书的导语就先来谈编程思维,包括如何理解编程语言,用数学建模的思维引领读者从理解实际 问题到自己写代码解决问题,了解R 语言的编程思想(面向函数、面向对象、面向向量)。
第 1 章是讲述 R 语言编程的基本语法,同时涉及向量化编程、函数式编程。这些语法在其他编 程语言中也是相通的,包括搭建 R 语言环境以及常用数据结构(存放数据的容器),例如向量、 矩阵、数据框、因子、字符串(及正则表达式)、日期时间, 此外还涉及分支结构、循环结构、自定义函数 等。这些基本语法是编写 R 代码的基本元素,学透它们非常重要, 只有学透它们才能将其任意组合、 恰当使用,以写出解决具体问题的R 代码。同样是讲 R 的基本语法,本书的不同之处在于,用 tidyverse 中更一致、更好用的相应包加以代替,例如用tibble代替 data.frame、用 forcats 包处理因子、用 stringr 讲字符串(及正则表达式)、用 lubridate 包讲日期时间、在循环结构 中用 purrr 包的map_* 函数代替 apply 系列函数,另外还特别讲到泛函式编程。
第 2 章正式进入 tidyverse 核心部分,即数据操作。本章侧重讲解数据思维, 先简单介绍 tidyverse 包以及编程技术之管道操作,接着围绕各种常用数据操作展开,包括数据读写(各种常 见数据文件的读写及批量读写、用 R 连接数据库、中文编码问题及解决办法),数据连接(数据按行/ 列拼接、SQL 数据库连接),数据重塑(“脏”数据变“整洁”数据, 长宽表转换、拆分与合并列),数 据操作(选择列、筛选行、对行进行排序、修改列、分组汇总)、其他数据操作(按行汇总、窗口函数、 滑窗迭代、整洁计算),以及 data.table 基本使用(常用数据操作的 dplyr 语法与data.table语法对照)。tidyverse 最大的优势就是以“管道流”和“整洁语法”操作数据, 这些语法真正让数 据操作从 Base R 的晦涩、难记、难用, 到 tidyverse 的“一致”“整洁”、好记、好用, 甚至比 Python 的pandas还好用!为了最大限度地降低理解负担, 本书特意选用中文的学生成绩数据作为演示数据, 让读者只关心语法就好。另外, tidyverse 的这些数据操作,实际上已经在语法层面涵盖了日常 Excel 数据操作、 SQL 数据库操作, 活用 tidyverse 数据操作语法已经可以完成很多常见任务。
第 3 章是可视化与建模技术。可视化只介绍流行的可视化包ggplot2,先从 ggplot2 的 图层化绘图语法开始, 依次介绍 ggplot2 的九大部件:数据、映射、几何对象、标度、统计变 换、坐标系、分面、主题、输出; 接着介绍功能上的图形分类:类别比较图、数据关系图、数据分布图、时间序列图、局部整体图、地理空间图, 对每一类图形分别选择其中有代表性的用实例加以演示。建模技术包括三项内容: (1)用 broom 包提取统计模型结果为整洁数据框,方 便后续访问和使用; (2) modelr 包中一些有用的辅助建模函数;(3)批量建模技术, 例如要对 全国各地的数据分别建立模型、提取模型结果,当然这可以用 for 循环实现,但这里采用更加 优雅的 map_*以及“行化迭代”实现。
第 4 章是统计应用。 R 语言是专业的统计分析软件,广泛应用于统计分析与计算领域。本章将 从 4 个方面展开: (1)描述性统计,介绍适合描述不同数据的统计量、统计图、列联表; (2)参数 估计,主要介绍点估计与区间估计,包括Bootstrap 法估计置信区间,以及常用的参数估计方法 (最小二乘估计、最大似然估计);(3)假设检验,介绍假设检验原理,基于理论的假设检验(以方 差分析、卡方检验为例,并用整洁的 rstatix 包实现),以及基于重排的假设检验(以 t检验为 例,用 infer 包实现);(4)回归分析,从线性回归原理、回归诊断,借助具体实例讲解多元线 性回归的整个过程,并介绍广泛应用于机器学习的梯度下降法以及广义线性模型原理。
第 5 章,探索性数据分析。主要讨论三方面内容:(1) 数据清洗,包括缺失值探索与处理、 异常值识别与处理; (2)特征工程, 包括特征缩放(标准化、归一化、行规范化、数据平滑)、特征变换(非线性特征、正态性变换、连续变量离散化)、基于 PCA 的特征降维; (3)探索变量 间的关系,包括分类变量之间、分类变量与连续变量之间、连续变量之间的关系。
第 6 章,文档沟通,讨论如何进行可重复研究,用 R markdown 家族生成各种文档,介绍 Rmarkdown 的基本使用, R 与 Latex 交互编写期刊论文、 PPT、图书、R 与 Git/Github 交互进行 版本控制、用 R Shiny 轻松制作交互网络应用程序(Web App)以及开发和发布 R 包的工作流程。
附录部分是对正文内容的补充和扩展,分别介绍错误与调试、R6类面向对象编程、实现 Excel中的VLOOKUP与透视表、 R 网络爬虫、R 高性能计算、R 机器学习框架 —mlr3verse 和 tidymodels。
大家可以根据自己的需求选择阅读侧重点,不过我还是希望你能够按照顺序完整地阅读, 这样才能彻底地更新一遍你的 R 知识, 避免 base R 与 tidyverse 混着用, 因为二者在写 R 代码上不是一种思维, 强行搭在一起反而效率低。
本书所用的软件
本书在编写时,使用当时最新的 R语言 4.2.1 和RStudio 2022.02.3,使用的 R包主要是 tidyverse 1.3.1 系列。
本书的配套资源下载
本书的R 程序均作为Rmarkdown 中的代码调试通过,所有示例的数据、R 程序、教学PPT 都可 以在异步社区官网、Github (https://github.com/zhjx19/introR)、码云(https://gitee.com/zhjx19/introR)下载。
部分致谢
感谢 Hadley 的《R 数据科学》(Rfor Data Science) 让我实现了 tidy 方式的数据科学入门; 感谢 Desi Quintans 和 Jeff Powell 的 Working in theTidyverse 让我真正开始对用 tidyverse操作数据 产生兴趣。也正是这些启蒙和启发令本书得以诞生。