#首先生成数据
library(dplyr)
df <- data.frame(sample(letters, 26), sample(26), sample(26), sample(26), sample(26), sample(26), sample(26), sample(26), sample(26), sample(26), sample(26))
row_name <- c(sample(letters, 26))
row.names(df) <- row_name
col_name <- c('ID', 'A_1', 'A_3', 'B_1', 'B_2', 'B_3', 'C_1', 'C_2', 'D_1', 'D_2', 'D_3')
colnames(df) <- col_name
df <- as_tibble(df)
df
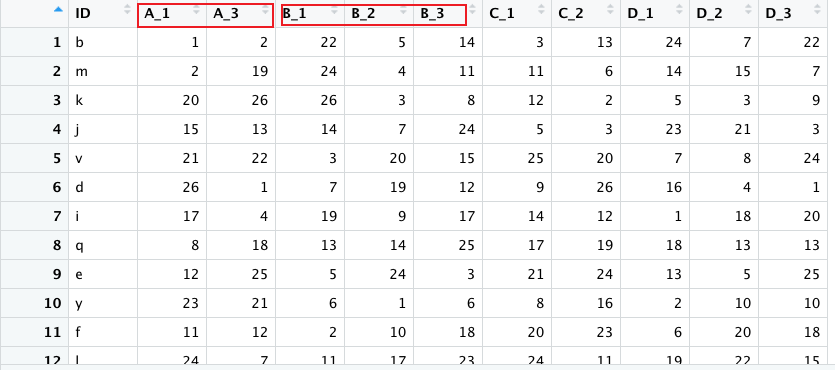
如图所示,请以每列相似前缀列名的为一组,计算它们在每一行的均值。
最后的结果希望得到如下图的数据框:
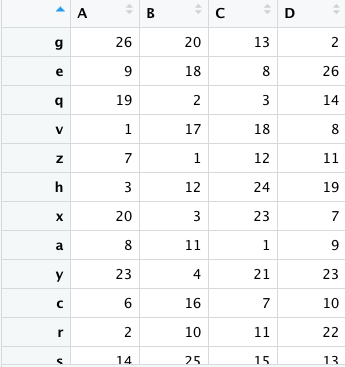
困扰了一下的问题,虽然最后自己解决的了,但是代码十分繁琐,所以就不把代码贴出来了。我相信会有兄弟有更好的解决方法。