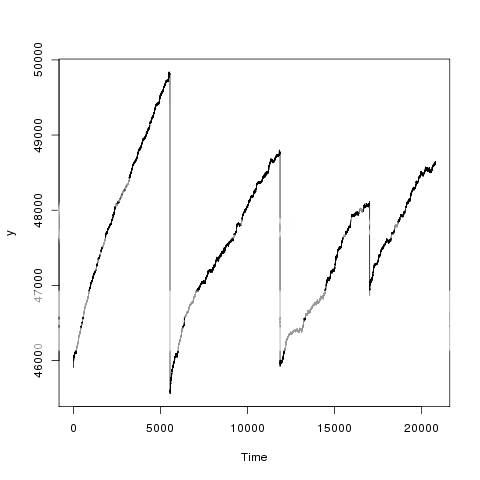
HarryYu 这个图片的解释是,这是四天采集的timeseries数据,大约每天采集5000个点,大于5000或者小于5000,构成x坐标。每个采样点的数值,构成y坐标。 这个图形直观上很容易看出规律,但是我用arima预测的话,预测出来的曲线,根本不能满足我的想法。预测出来的不是一条大概的倾斜的直线,而是一条很离谱的水平线。比如预测4000个点,预测结果是4000个大体相等的y值。 查了一下arima.pdf里面的介绍,应该为观察数据指定frequency。比如,我对每天的数据划分为300份,frequency=300(frequency=4000的话,会超出内存)。这样做的话,数据是有损失的。这是一组很敏感的数据,一旦采样完成,希望把每个采样点的数据都纳入程序处理。 这个问题困扰了我很长时间,特地发出来,征求大家的帮助。
HarryYu 这个问题,不想继续被困住了。我的解法是这样的, [data] 1 求出y出现的次数,比如y1(2),y2(3),y3(6)...表示y1出现了2次,y2出现了3次,y3出现了6次,等等。 2 将次数从大到小进行排序,比如2,3,6,8,6,3,2,5,排序的结果是,8,6,6,5,3,3,2,2 3 取出前4000个排序对应的y值,返回 [/data] 喜欢思考的人,可以好好想想这个解法,这个解法即便是我自己想出来的,也感觉里面是相当有深度的。这个解法让我很有压力。
yihui 这个问题中日期真的有意义吗?我估计没有(当然你可以把日期加进来检验一下是否显著)。换句话说,只有某一天当中的观测时刻是有用的自变量,那么你把横坐标上的四条线压缩到同一天内做模型就好了(比如对时间回归之类的,不是所有时间序列非用ARIMA不可),预测的时候可以不必管具体日期。
HarryYu 是,但是纵轴并不是价格,而是价格的一个映射。但是我已经快忘的差不多了。我现在偶尔会关注J-Chart,但是投入的时间并不多,但是J的计算模型已经接近于完全作出来了,并且包括了对J的证明和反证,并且在当代的计算环境下可以很容易的得以实现。